
fdupes Linux là một giải pháp hữu ích và trực quan dành cho người dùng Linux khi cần kiểm soát dữ liệu trùng lặp trên ổ lưu trữ. Trong bài viết này, mình sẽ cùng bạn tìm hiểu rõ về lệnh fdupes, đồng thời tham khảo cách sử dụng fdupes để tìm và xóa các file bị trùng lặp hiệu quả, nhanh chóng nhất.
Những điểm chính
- Định nghĩa lệnh fdupes Linux: Hiểu rõ khái niệm và mục đích chính của fdupes trong việc quét và nhận diện các file trùng lặp để quản lý không gian lưu trữ.
- Cách fdupes hoạt động: Nắm được cơ chế hoạt động của fdupes, từ việc lọc theo kích thước, so sánh hash đến kiểm tra byte-by-byte để đảm bảo độ chính xác.
- Các tùy chọn phổ biến: Có được một bảng tra cứu nhanh các tùy chọn quan trọng, giúp bạn tùy chỉnh việc tìm kiếm và xử lý file trùng lặp.
- Các tính năng chính: Biết được các khả năng cốt lõi của fdupes như tìm kiếm toàn diện, tùy biến thao tác xóa và hiệu suất tối ưu.
- Cách cài đặt: Nắm vững các lệnh cài đặt fdupes trên các bản phân phối Linux phổ biến như Ubuntu và CentOS.
- Cách sử dụng chi tiết: Thành thạo các ví dụ sử dụng thực tế, từ việc tìm kiếm, hiển thị kích thước đến xóa file trùng lặp một cách an toàn.
- Lưu ý khi sử dụng: Nắm được các nguyên tắc quan trọng để sử dụng fdupes một cách an toàn, tránh mất dữ liệu không thể khôi phục.
- Các công cụ thay thế: Biết đến các công cụ khác như Uniq hay FsLint để có thêm lựa chọn khi xử lý các dạng dữ liệu trùng lặp khác nhau.
- Giải đáp thắc mắc (FAQ): Có được câu trả lời cho các vấn đề thực tế như mức độ an toàn, khả năng khôi phục và khi nào nên cân nhắc các giải pháp khác.
fdupes Linux là gì?
Fdupes là tiện ích dòng lệnh mã nguồn mở trên Linux, do Adrian Lopez phát triển và được phân phối theo giấy phép MIT. Công cụ này dùng để phát hiện và loại bỏ các file trùng lặp trong thư mục và thư mục con bằng cách so sánh kích thước, mã băm MD5 và nội dung từng byte. Nhờ đó, fdupes giúp người dùng dọn dẹp hệ thống, giải phóng dung lượng lưu trữ và quản lý dữ liệu hiệu quả hơn.

Cách hoạt động của fdupes
Công cụ này hoạt động theo các bước như sau:
- Lọc file theo kích thước để giảm số lượng file cần so sánh.
- Tính mã hash MD5 cho từng file để phát hiện file nghi ngờ trùng lặp.
- So sánh mã hash để xác định nhóm file trùng.
- So sánh từng byte để đảm bảo kết quả chính xác tuyệt đối.
Ngoài ra, fdupes cũng hỗ trợ quét đệ quy thư mục con, hiển thị chính xác đường dẫn file trùng lặp và cho phép xóa file trùng lặp theo lựa chọn của người dùng. Đây là công cụ mạnh mẽ giúp quản lý, tổ chức lại dữ liệu và giải phóng không gian lưu trữ trên máy tính hoặc server một cách hiệu quả.

Các tùy chọn phổ biến của fdupes trong Linux
| Tùy chọn | Tên đầy đủ | Chức năng |
|---|---|---|
| -r | --recurse | Tìm kiếm đệ quy trong tất cả các thư mục con của mọi thư mục được cung cấp. |
| -R | --recurse: | Tìm kiếm đệ quy chỉ trong các thư mục con được chỉ định ngay sau tùy chọn này. |
| -s | --symlinks | Theo dõi và xem xét các liên kết tượng trưng trong quá trình quét. |
| -H | --hardlinks | Coi các liên kết cứng trỏ đến cùng một file là các bản sao trùng lặp. |
| -n | --noempty | Loại trừ các file có kích thước bằng 0 khỏi kết quả. |
| -A | --nohidden | Loại các file ẩn khỏi quá trình xem xét. |
| -f | --omitfirst | Bỏ qua việc hiển thị file đầu tiên trong mỗi nhóm file trùng lặp. |
| -1 | --sameline | Liệt kê mỗi nhóm file trùng lặp trên một dòng duy nhất, phân tách bằng dấu cách. |
| -S | --size | Hiển thị kích thước của các file trùng lặp được tìm thấy. |
| -m | --summarize | Cung cấp một báo cáo tóm tắt về tổng số file trùng lặp và dung lượng chúng chiếm dụng. |
| -q | --quiet | Ẩn chỉ báo tiến trình quét, chỉ hiển thị kết quả cuối cùng. |
| -v | --version | Hiển thị thông tin phiên bản của fdupes đã được cài đặt. |
| -h | --help | Hiển thị màn hình trợ giúp với danh sách đầy đủ các tùy chọn. |
Các tính năng chính của fdupes
- Tìm kiếm toàn diện: Tự động phát hiện các file trùng lặp không chỉ trong thư mục chính mà còn bao gồm toàn bộ hệ thống thư mục con liên quan.
- Tùy biến thao tác: Cung cấp nhiều lựa chọn như hiển thị danh sách file trùng lặp, tiến hành xóa hoặc thay thế chúng bằng liên kết cứng tùy theo nhu cầu quản trị.
- Tối ưu hiệu suất: Công cụ nhẹ, tốc độ xử lý nhanh, được đánh giá cao về độ tin cậy và thường xuyên được sử dụng trên các hệ thống Linux, kể cả môi trường máy chủ chuyên nghiệp.

Cách cài đặt fdupes
Trên Ubuntu/Debian:
sudo apt update
sudo apt install fdupesTrên Fedora/CentOS:
sudo dnf install fdupes # Fedora / CentOS 8+
sudo yum install fdupes # CentOS 7Kiểm tra phiên bản:
fdupes --versionSau khi chạy lệnh kiểm tra, kết quả hiển thị phiên bản hiện tại đang là 2.3.0:

Cách sử dụng lệnh fdupes chi tiết
1. Xem trợ giúp và tùy chọn có sẵn
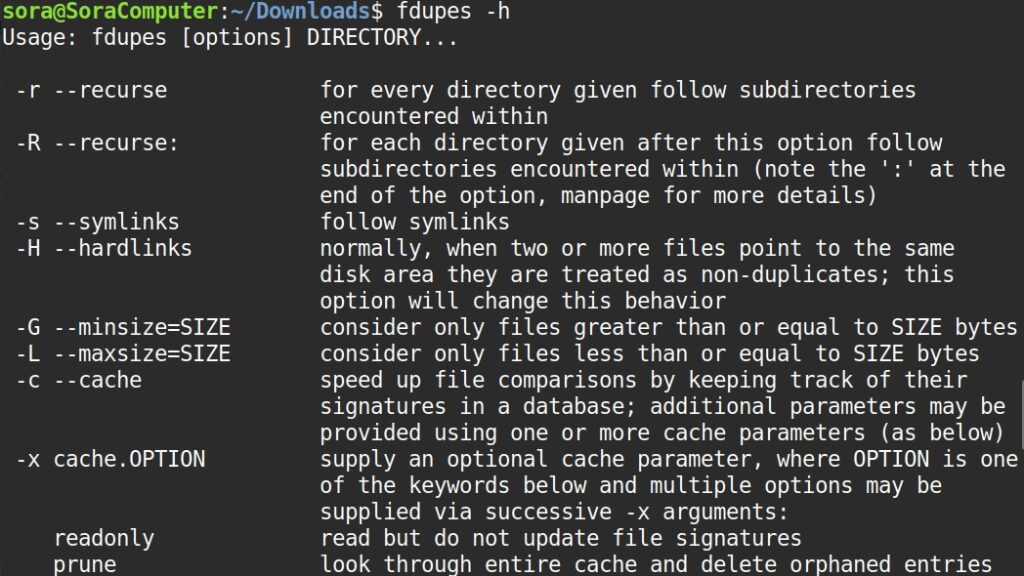
Để hiển thị danh sách đầy đủ các tham số và cú pháp hỗ trợ của chương trình, bạn thực thi lệnh sau:
fdupes -hKết quả hiển thị đầy đủ như sau:
2. Tìm file trùng trong một thư mục
Bạn thực thi lệnh bên dưới đây để quét và nhóm các file có nội dung giống nhau nằm trong một thư mục cụ thể:
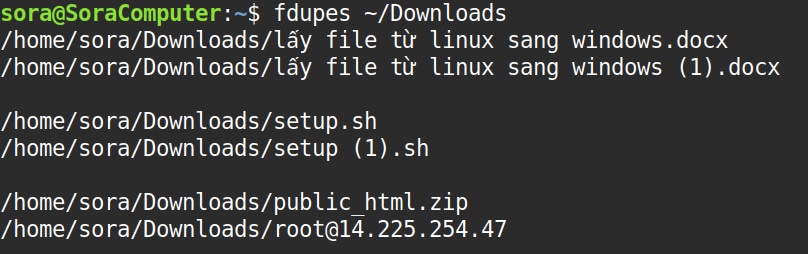
fdupes /duong/dan/thu_mucVí dụ:
fdupes ~/DownloadsLệnh sẽ liệt kê các nhóm file trùng nhau và trả về kết quả:
3. Hiển thị toàn bộ đường dẫn file
Tùy chọn -f sẽ yêu cầu hệ thống hiển thị đường dẫn đầy đủ từ thư mục gốc, giúp định vị chính xác vị trí file, đặc biệt khi quét trên diện rộng:
fdupes -f /duong/dan/thu_mucBạn có thể kết hợp -r -f để quét toàn bộ cây thư mục và xem chính xác từng file:
fdupes -rf /home/user4. Quét đệ quy các thư mục con
Bạn sử dụng tùy chọn -r để mở rộng phạm vi tìm kiếm vào tất cả các thư mục con nằm bên trong thư mục đích.
fdupes -r /duong/dan/thu_muc5. Hiển thị kích thước của file trùng
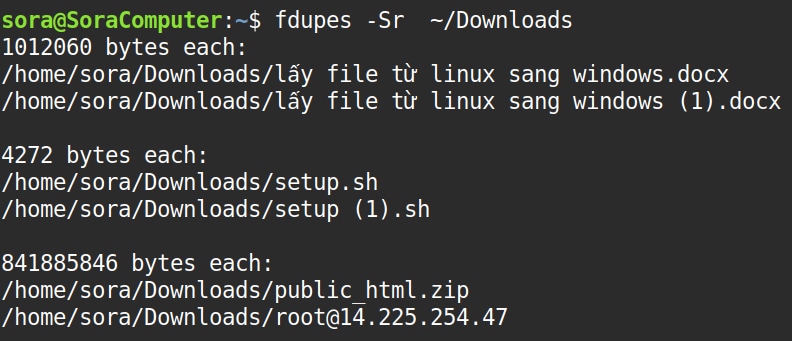
Lệnh dưới đây kết hợp tùy chọn -S (Size) để hiển thị kích thước của các file trùng, hỗ trợ quản trị viên đánh giá mức độ tiêu tốn dung lượng lưu trữ của các dữ liệu dư thừa.
fdupes -Sr /duong/dan/thu_mucTrong đó:
- -S: Hiển thị kích thước file.
- -r: Quét đệ quy.
Lệnh giúp bạn biết các nhóm file trùng đang chiếm bao nhiêu dung lượng:
6. Xóa file trùng có xác nhận thủ công
Bạn sử dụng tùy chọn -d để kích hoạt trình hướng dẫn xóa. Hệ thống sẽ liệt kê từng nhóm file trùng và yêu cầu người dùng xác nhận hành động cụ thể.
fdupes -d /duong/dan/thu_mucTại mỗi nhóm file, hệ thống sẽ đưa ra lời nhắc và bạn cần nhập số thứ tự của file muốn giữ lại:
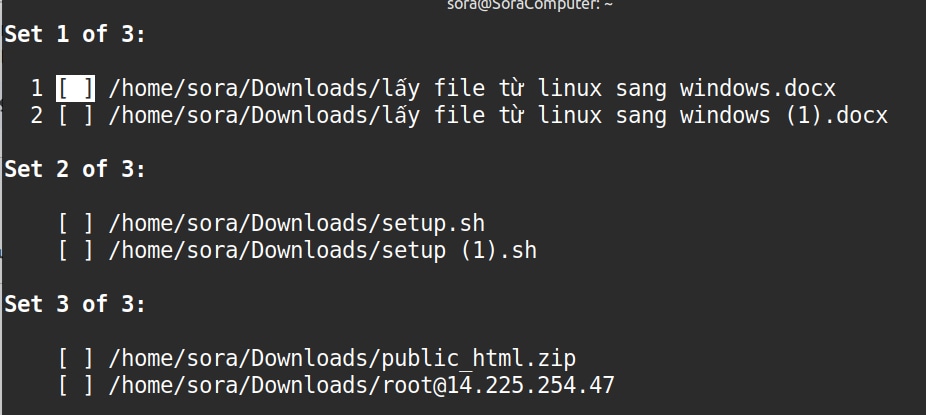
Bạn có thể nhập:
- 1, 2: Giữ lại file tương ứng, xóa các file còn lại trong nhóm.
- all: Giữ lại tất cả, không xóa file nào trong nhóm.
- none: Bỏ qua nhóm hiện tại, không làm gì cả.
Mỗi nhóm sẽ được xử lý riêng, lệnh sẽ lặp lại cho nhóm tiếp theo nếu có.
![]() Lưu ý
Lưu ý
Khi bạn đã chọn file để giữ, các file còn lại trong nhóm sẽ bị xóa ngay và không có bước xác nhận lại. Vì vậy bạn hãy kiểm tra kỹ trước khi chọn, trong trường hợp bạn cần dừng tiến trình thì nhấn Ctrl + C.
7. Xóa file trùng không cần xác nhận
Bạn sử dụng tùy chọn -N kết hợp với -d để thực hiện xóa hàng loạt mà không cần hỏi lại người dùng.
fdupes -dN /duong/dan/thu_mucHệ thống sẽ tự động giữ lại file đầu tiên trong mỗi nhóm trùng lặp và xóa tất cả các file còn lại.
![]() Lưu ý
Lưu ý
Chỉ sử dụng lệnh này khi bạn đã chắc chắn về cấu trúc dữ liệu hoặc đã có phương án sao lưu, vì dữ liệu bị xóa sẽ không thể khôi phục.
Một số lưu ý khi sử dụng fdupes
- Nguyên tắc an toàn dữ liệu: Bạn hãy chạy lệnh fdupes ở chế độ quét thông thường, không kèm tùy chọn -d để rà soát, đồng thời kiểm tra chính xác danh sách các file trùng lặp trước khi tiến hành xóa.
- Cơ chế xác định trùng lặp: fdupes không so sánh theo tên file hay ngày tạo, mà dựa hoàn toàn vào nội dung.
- Giới hạn về khả năng nhận diện: Phần mềm chỉ tìm kiếm các file giống nhau tuyệt đối và không hỗ trợ tính năng tìm kiếm gần giống, nếu có nhu cầu này, bạn nên tham khảo các công cụ thay thế như rdfind hoặc fslint.
- Tính chất không thể khôi phục: Các thao tác xóa thực hiện bởi fdupes sẽ loại bỏ dữ liệu vĩnh viễn khỏi ổ cứng và không lưu vào thùng rác, vì vậy dữ liệu sẽ không thể khôi phục lại sau khi lệnh đã thực thi.
Các công cụ hỗ trợ xử lý dữ liệu trùng lặp khác
Linux cung cấp nhiều tiện ích khác có thể hỗ trợ bạn trong việc xử lý các dạng dữ liệu trùng lặp:
- Uniq: Được sử dụng chuyên biệt để tìm và xóa các dòng trùng lặp liền kề trong các file văn bản.
- Duperemove: Là công cụ xử lý dữ liệu trùng lặp được thiết kế để hoạt động ở cấp độ hệ thống file, đặc biệt hiệu quả với các hệ thống file hiện đại như btrfs và XFS.
- FsLint: Công cụ này không chỉ tìm file trùng lặp mà còn có thể xác định các liên kết tượng trưng bị hỏng, thư mục trống, và các vấn đề khác liên quan đến hệ thống tệp.

Câu hỏi thường gặp
Vì sao sử dụng fdupes khi dọn dẹp file trùng lặp an toàn hơn so với việc xóa thủ công?
Fdupes sử dụng thuật toán so sánh nội dung file qua hash MD5 và kiểm tra từng byte, đảm bảo chỉ phát hiện các file thực sự giống nhau, giảm nguy cơ xóa nhầm các file quan trọng chỉ cùng tên hoặc cùng kích thước nhưng khác nội dung.
Vì sao nên sử dụng tuỳ chọn -d khi dọn dẹp file bằng fdupes thay vì -dN?
Tùy chọn -d kích hoạt xác nhận thủ công, giúp kiểm tra lại từng nhóm file trùng và chọn file giữ lại, đặc biệt hữu ích khi dữ liệu quan trọng hoặc bố cục thư mục phức tạp. Dùng -dN sẽ tự động xóa tất cả ngoại trừ file đầu, dễ gây mất dữ liệu nếu không kiểm tra kỹ.
Sau khi sử dụng fdupes xóa file, có thể khôi phục lại không?
Không, thao tác xóa bằng fdupes là vĩnh viễn – file bị xóa ngay, không chuyển vào thùng rác hay vùng tạm lưu, không thể phục hồi bằng công cụ thông thường. Vì vậy, luôn kiểm tra kỹ hoặc sao lưu dữ liệu quan trọng trước khi xóa.
Trường hợp nào nên cân nhắc giải pháp khác ngoài fdupes?
Nên cân nhắc các công cụ khác như rdfind, duperemove, hoặc FsLint nếu có nhu cầu tìm kiếm gần giống, kiểm tra liên kết tượng trưng bị hỏng, thư mục trống hoặc các vấn đề khác trong hệ thống tệp, vì fdupes chỉ chuyên về file trùng lặp tuyệt đối.
fdupes là một giải pháp hữu ích và trực quan dành cho người dùng Linux khi cần kiểm soát dữ liệu trùng lặp trên ổ lưu trữ. Nhờ khả năng quét sâu toàn bộ hệ thống thư mục, tích hợp nhiều tùy chọn thao tác và đảm bảo hiệu suất xử lý, công cụ này giúp tối ưu không gian lưu trữ và tổ chức dữ liệu cá nhân hoặc hệ thống máy chủ một cách an toàn, chuyên nghiệp. Mời bạn theo dõi thêm các bài viết về chủ đề Linux bên dưới đây:




