
gawk trong Linux là một trình thông dịch dòng lệnh thuộc hệ sinh thái AWK, được GNU triển khai, dùng để xử lý, phân tích và định dạng dữ liệu văn bản, đặc biệt là dạng dữ liệu cột. Với khả năng phân tích, trích xuất và định dạng dữ liệu có cấu trúc một cách linh hoạt, gawk cho phép các quản trị viên hệ thống và nhà phát triển giải quyết các bài toán phức tạp chỉ bằng dòng lệnh ngắn gọn. Trong bài viết dưới đây, mình sẽ cùng bạn tìm hiểu chi tiết về lệnh gawk, từ định nghĩa, cú pháp cho đến các ví dụ ứng dụng thực tế của lệnh này.
Những điểm chính
- Định nghĩa lệnh gawk Linux: Hiểu rõ định nghĩa, vai trò và cú pháp cơ bản của
gawktrong việc xử lý và định dạng dữ liệu văn bản. - Cơ chế hoạt động: Nắm được quy trình xử lý dữ liệu theo từng dòng của
gawk(record, pattern, action) để áp dụng lệnh một cách chính xác. - Các biến tích hợp: Biết cách sử dụng các biến quan trọng như
NR,NF,FSđể thực hiện các tác vụ đếm và phân tích nâng cao. - Mối liên hệ giữa awk, nawk và gawk: Hiểu rõ mối quan hệ giữa các phiên bản để tự tin sử dụng lệnh trên các hệ thống Linux khác nhau.
- Ví dụ sử dụng thực tế: Nắm vững cách áp dụng
gawkvào các tình huống thực tế như in cột, lọc dữ liệu và thay đổi ký tự phân tách. - Giải đáp thắc mắc (FAQ): Có được câu trả lời cho các câu hỏi thường gặp, giúp bạn giải quyết các vấn đề thực tế và hiểu sâu hơn về điểm mạnh của
gawk.
Lệnh gawk Linux là gì?
Định nghĩa
gawk Linux là phiên bản nâng cao của lệnh awk – một công cụ dòng lệnh mạnh mẽ trong Linux/Unix dùng để xử lý và phân tích văn bản, đặc biệt là dữ liệu có định dạng cột (như file CSV, log,…). Tiện ích này cho phép quản trị viên hệ thống và lập trình viên thực hiện các thao tác như trích xuất, lọc, tính toán và trình bày dữ liệu một cách linh hoạt chỉ bằng vài dòng lệnh, tiết kiệm thời gian so với các ngôn ngữ lập trình truyền thống.

Cú pháp sử dụng lệnhk gawk như sau:
gawk 'pattern { action }' filenameTrong đó:
- pattern: Là điều kiện tìm kiếm hoặc kiểm tra trên từng dòng dữ liệu lấy từ filename.
- { action }: Là tập hợp các câu lệnh sẽ được thực thi với dòng tìm thấy thỏa pattern.
- filename: Là đường dẫn đến file văn bản mà gawk sẽ đọc và xử lý tuần tự từng dòng.
Nguồn gốc ra đời
AWK là một ngôn ngữ lập trình kịch bản định hướng dữ liệu, xuất hiện lần đầu tiên vào năm 1977 tại phòng thí nghiệm AT&T Bell với mục tiêu chuyên biệt cho việc tìm kiếm mẫu và thao tác trên dữ liệu văn bản. Trên nền tảng đó, gawk ra đời dưới dạng bản triển khai của dự án GNU dành cho ngôn ngữ AWK.
Đến thời điểm hiện nay, gawk đã trở thành tiện ích dòng lệnh mặc định, phổ biến trên phần lớn các bản phân phối Linux hiện đại, giúp người dùng dễ dàng xử lý, phân tích dữ liệu văn bản một cách hiệu quả và linh hoạt.
Vai trò
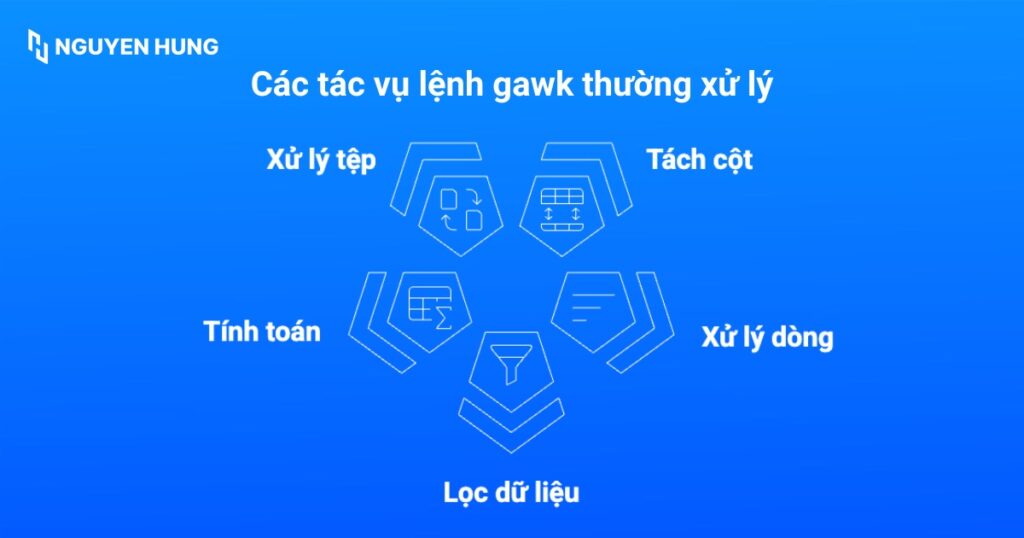
Vai trò cốt lõi của gawk là xử lý và định dạng dữ liệu trong các file văn bản, đặc biệt là các dữ liệu được tổ chức theo cột, cho phép người dùng dễ dàng trích xuất hoặc thao tác dữ liệu, tạo báo cáo, so khớp mẫu, và thực hiện các phép tính phức tạp. Cụ thể, lệnh gawk thường được sử dụng để xử lý các tác vụ như:
- Tự động thay đổi định dạng văn bản.
- Tách cột, xử lý dòng trong file.
- Lọc dữ liệu theo điều kiện.
- Tính toán (cộng cột, trung bình,…).
- Tự động xử lý log, báo cáo, CSV.
Điểm mạnh của gawk nằm ở khả năng hoàn thành các tác vụ phức tạp chỉ với một dòng mã ngắn gọn, tối ưu hơn hẳn so với các ngôn ngữ lập trình truyền thống như C hoặc Python. Hơn nữa, AWK cho phép sử dụng biến, các hàm tích hợp sẵn, và toán tử logic mà không yêu cầu quá trình biên dịch, mang lại sự linh hoạt và tốc độ trong quá trình phát triển kịch bản.
Cơ chế hoạt động của gawk
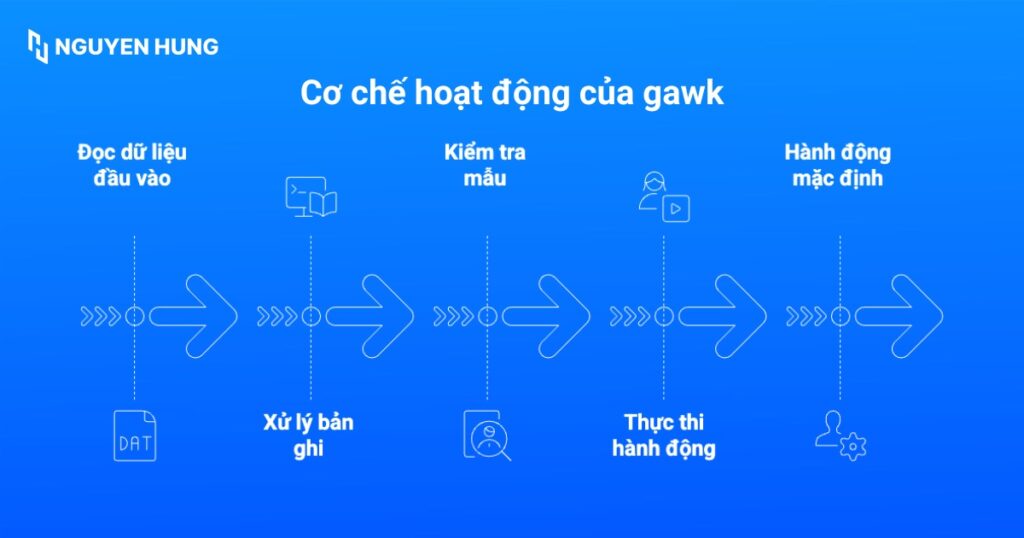
Cơ chế hoạt động của gawk tuân theo một quy trình tuần tự và lặp đi lặp lại:
Gawkđọc dữ liệu đầu vào, có thể từ đầu vào tiêu chuẩn (STDIN) hoặc từ một hay nhiều file được chỉ định.- Lệnh này tiến hành xử lý dữ liệu theo từng dòng, hay còn được gọi là bản ghi (record).
- Đối với mỗi bản ghi,
gawksẽ kiểm tra xem có khớp với mẫu (pattern) đã được định nghĩa hay không. - Nếu bản ghi khớp với mẫu, hành động (action) tương ứng trong dấu ngoặc nhọn
{}sẽ được thực thi trên bản ghi đó. - Trong trường hợp mẫu bị bỏ qua,
awksẽ mặc định thực hiện hành động trên tất cả các bản ghi đã đọc được.
Các biến tích hợp trong gawk
- NR: Đếm số dòng đầu vào đã xử lý (tính từ đầu đến hiện tại).
- NF: Đếm số trường trong dòng hiện tại.
- FS: Lưu ký tự phân các trường đầu vào.
- RS: Lưu ký tự phân cách giữa các bản ghi.
- OFS: Lưu ký tự phân cách giữa các trường khi truy xuất ra.
- ORS: Lưu ký tự phân cách giữa các bản ghi khi xuất ra.
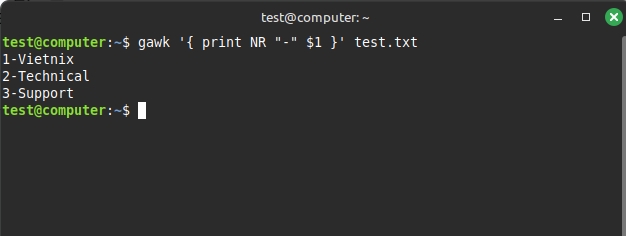
Ví dụ với NR:
gawk '{ print NR "-" $1 }' test.txtKết quả sau khi chạy như sau:
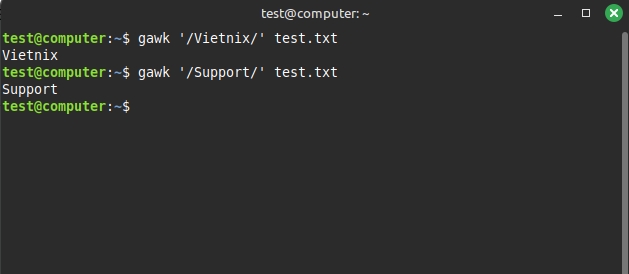
Tìm kiếm văn bản:
gawk '/Vietnix/' test.txtKết quả trả ra được hiển thị như sau:
Mối liên hệ giữa awk, nawk và gawk
Trên hầu hết các hệ thống Linux hiện nay, khi người dùng gõ lệnh awk hay nawk, thực chất họ đang gọi đến trình thông dịch gawk. Hai tên gọi này thường chỉ là các liên kết tượng trưng (symlinks) trỏ tới file thực thi của gawk. Phiên bản gawk không chỉ tuân thủ các tiêu chuẩn mới nhất của Bell Laboratories awk mà còn cung cấp nhiều tiện ích mở rộng độc quyền của GNU, làm cho gawk trở thành phiên bản mạnh mẽ và đầy đủ tính năng nhất hiện nay.
Ví dụ sử dụng lệnh gawk thực tế
In ra tất cả nội dung trong file test.txt
gawk '{print}' test.txtKết quả trả ra như sau:
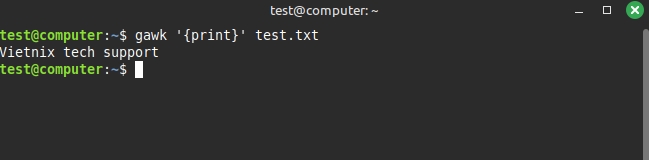
In ra cột đầu tiên được phân cách bằng dấu cách
gawk '{print $1}' test.txtKết quả hiển thị như sau:
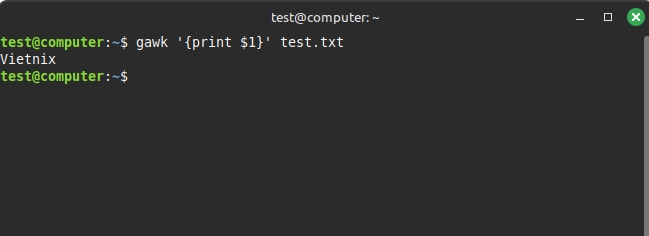
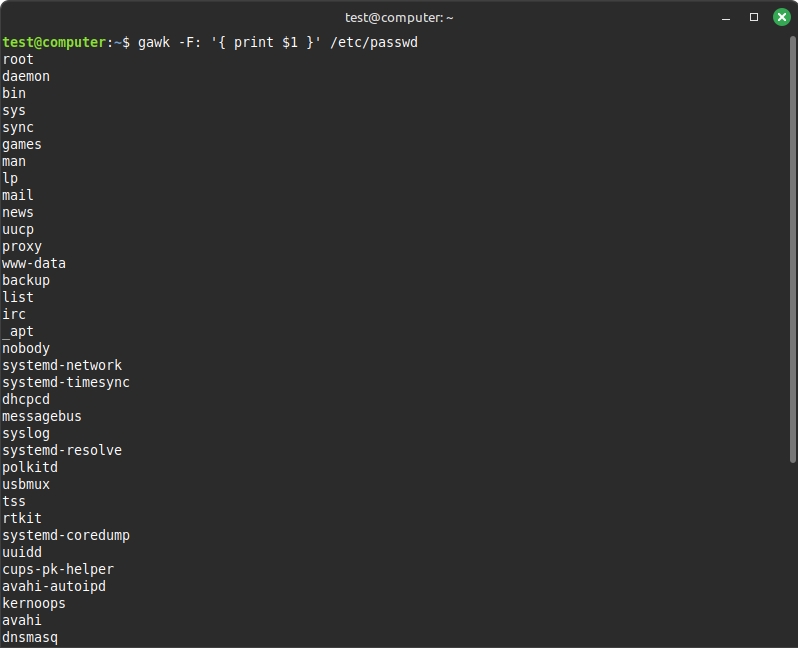
Chỉ định dấu phân cách trường bằng tùy chọn -F
gawk -F: '{ print $1 }' /etc/passwdKết quả hiển thị như sau:
Câu hỏi thường gặp
gawk xử lý nhiều file đầu vào như thế nào?
gawk đọc lần lượt từng file và áp dụng cùng mã lệnh cho từng dòng, thuận tiện cho phân tích dữ liệu từ nhiều nguồn.
Điểm mạnh của gawk so với Python, C trong xử lý văn bản là gì?
gawk có cú pháp ngắn, chạy trực tiếp dòng lệnh, phù hợp xử lý nhanh mà không cần biên dịch hay viết script dài dòng.
Cách đổi ký tự phân tách trường trong gawk?
Bạn có thể dùng tùy chọn -F, ví dụ: gawk -F, ‘{print $2}’ file.csv.
gawk dùng NR, NF để thống kê gì mà grep, sed không làm được?
gawk dùng NR, NF để đếm số dòng, số cột từng dòng, tổng số trường, phân loại dữ liệu theo trường – đây là những thống kê grep/sed khó thực hiện.
Gawk là một công cụ cực kỳ mạnh mẽ và linh hoạt, đóng vai trò quan trọng trong việc xử lý dữ liệu trên các hệ thống Linux, đặc biệt là với các dữ liệu được sắp xếp theo cột. Khả năng kết hợp giữa so khớp mẫu, thao tác trên từng trường và thực hiện tính toán ngay trên dòng lệnh giúp gawk trở thành một giải pháp hiệu quả để nhanh chóng trích xuất thông tin, tạo báo cáo, hoặc tự động hóa các hoạt động xử lý văn bản phức tạp. Việc thành thạo gawk Linux sẽ trang bị cho bạn một kỹ năng hữu ích, giúp tiết kiệm thời gian và công sức trong các tác vụ quản trị hệ thống hàng ngày.




