
Uniq Linux là lệnh dòng lệnh dùng để phát hiện, báo cáo hoặc loại bỏ các dòng trùng lặp liền kề trong file văn bản hoặc dữ liệu nhận từ stdin, thường được dùng cùng sort để lọc và chuẩn hóa danh sách trên hệ thống Linux. Trong bài viết này, với kinh nghiệm nhiều năm trong System, Network Linux mình sẽ cùng bạn tìm hiểu chi tiết cú pháp, các tùy chọn thường dùng, ví dụ thao tác thực tế và lưu ý quan trọng khi sử dụng uniq linux để xử lý dữ liệu hiệu quả hơn.
Những điểm chính
Quan điểm của mình về uniq: Lệnh uniq hiếm khi được dùng độc lập mà thường đi kèm với lệnh sort. Trong các tác vụ quản trị hệ thống và xử lý dữ liệu, việc kết hợp sort | uniq là một phương pháp tiêu chuẩn và hiệu quả. Nó cho phép lọc các dòng trùng lặp và thống kê tần suất xuất hiện của chúng từ một tập dữ liệu lớn chưa qua xử lý. Việc sử dụng thành thạo chuỗi lệnh này là một kỹ năng thiết yếu để phân tích dữ liệu dạng văn bản trên dòng lệnh.
- Khái niệm: Hiểu rõ lệnh
uniqlà công cụ dùng để lọc các dòng trùng lặp liền kề, giúp bạn nhanh chóng làm sạch và tổ chức lại dữ liệu văn bản. - Cú pháp lệnh
uniq: Nắm vững cấu trúc và các thành phần của lệnh để lọc dữ liệu từ file hoặc đầu vào chuẩn một cách linh hoạt. - Các tùy chọn lệnh
uniq: Nắm vững các tham số chính để lọc và hiển thị dữ liệu theo nhu cầu, như đếm số lần xuất hiện, chỉ lấy dòng trùng hoặc duy nhất. - Ví dụ thực tế lệnh
uniq: Nắm vững cách áp dụng các tùy chọn vào các tình huống lọc và thống kê dữ liệu thực tế. - Lưu ý quan trọng: Nắm được các lưu ý và các lỗi thường gặp, đặc biệt là việc cần kết hợp với lệnh
sort, giúp bạn sử dụng lệnh một cách an toàn, chính xác và tránh các kết quả không mong muốn. - Câu hỏi thường gặp: Giải đáp các thắc mắc liên quan đến
uniqLinux.
Lệnh uniq trong Linux là gì?
Lệnh uniq trong Linux là lệnh dùng để phát hiện, báo cáo hoặc loại bỏ các dòng trùng lặp liền kề trong một file văn bản hoặc trong dữ liệu nhận từ đầu vào chuẩn, giúp làm sạch và tổ chức lại danh sách dữ liệu. Lệnh uniq có thể chỉ hiển thị các dòng duy nhất, chỉ hiển thị các dòng bị lặp, hoặc kèm thêm số lần xuất hiện của từng dòng thông qua các tùy chọn như -u, -d, -c, đồng thời thường được kết hợp với lệnh sort vì uniq chỉ xử lý các dòng trùng lặp nằm cạnh nhau mà không tự sắp xếp dữ liệu.
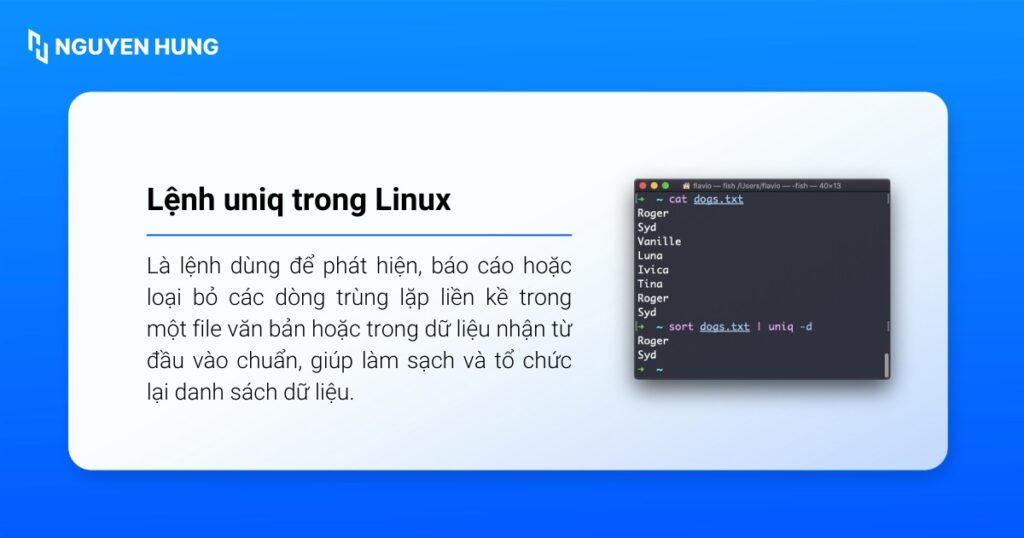
Cú pháp lệnh uniq trong Linux là gì?
Cú pháp lệnh uniq mô tả cách lệnh nhận dữ liệu đầu vào, áp dụng các tùy chọn lọc và xuất kết quả ra màn hình hoặc file, từ đó dễ dàng tích hợp vào các pipeline xử lý văn bản trên Linux.
Cú pháp: uniq [OPTIONS] [INPUT_FILE [OUTPUT_FILE]].
Trong đó:
OPTIONS: Không bắt buộc, dùng để điều chỉnh cách lọc và hiển thị như đếm số lần xuất hiện (-c), chỉ hiển thị dòng trùng (-d), chỉ cho ra 1 dòng duy nhất (-u), bỏ qua phân biệt chữ hoa – chữ thường (-i), giới hạn số ký tự so sánh (-w N), bỏ qua một số ký tự đầu dòng (-s N),…INPUT_FILE: File đầu vào cần xử lý; nếu không chỉ định, uniq sẽ đọc dữ liệu từ stdin, thường được sử dụng khi kết hợp với các lệnh khác qua pipe nhưsorthoặccat.OUTPUT_FILE: File đầu ra ghi lại kết quả đã lọc; nếu không chỉ định,uniqsẽ hiển thị kết quả trực tiếp ra terminal, thuận tiện cho việc xem nhanh hoặc tiếp tục chuyển tiếp sang lệnh khác.
Các tùy chọn thường dùng của lệnh uniq Linux
Các tùy chọn thường dùng của lệnh uniq giúp kiểm soát cách lọc và hiển thị các dòng trùng lặp, từ việc đếm số lần xuất hiện, chỉ lấy dòng trùng, chỉ lấy dòng duy nhất cho đến điều chỉnh phạm vi ký tự dùng để so sánh.Dưới đây là bảng tổng hợp chi tiết:
| Tùy chọn | Cú pháp ví dụ | Chức năng |
-c, --count | uniq -c input.txt | Thêm số đếm ở đầu mỗi dòng để cho biết số lần dòng đó xuất hiện liên tiếp trong dữ liệu đầu vào. |
-d, --repeated | uniq -d input.txt | Chỉ cho ra các dòng bị trùng lặp (xuất hiện từ 2 lần trở lên), bỏ qua các dòng chỉ xuất hiện một lần. |
-u, --unique | uniq -u input.txt | Kết quả là các dòng xuất hiện đúng một lần, loại bỏ toàn bộ các dòng có bản ghi trùng lặp. |
-i, --ignore-case | uniq -i input.txt | So sánh không phân biệt chữ hoa và chữ thường khi phát hiện trùng lặp, ví dụ “Apple” và “apple” được xử lý là cùng một dòng. |
-w N, --check-chars=N | uniq -w 5 input.txt | Chỉ so sánh N ký tự đầu tiên của mỗi dòng để quyết định trùng lặp, phần ký tự sau N không ảnh hưởng đến kết quả. |
-s N, --skip-chars=N | uniq -s 3 input.txt | Bỏ qua N ký tự đầu dòng khi so sánh, thường dùng khi vài ký tự đầu là timestamp, ID hoặc prefix không cần xét trùng. |
-f N, --skip-fields=N | uniq -f 1 input.txt | Bỏ qua N trường đầu tiên (tách theo khoảng trắng) khi so sánh, chỉ dùng các trường phía sau để xác định trùng lặp. |
-z, --zero-terminated | Dùng trong pipeline NUL-delimited | Sử dụng ký tự NUL thay cho newline làm ký tự kết thúc dòng, hỗ trợ tốt khi xử lý dữ liệu có chứa xuống dòng đặc biệt. |
Cách sử dụng lệnh uniq kèm ví dụ thực tế
- Ví dụ 1: Lọc các dòng trùng lặp và hiển thị nội dung duy nhất
- Ví dụ 2: Hiển thị các dòng trùng và số lần trùng lặp
- Ví dụ 3: Chỉ hiển thị các dòng bị trùng lặp và các dòng duy nhất
- Ví dụ 4: Lọc trùng không phân biệt chữ hoa/chữ thường
- Ví dụ 5: Giới hạn so sánh theo N ký tự đầu dòng với -w
- Ví dụ 6: Bỏ qua N ký tự đầu dòng khi so sánh với -s
- Ví dụ 7: Bỏ qua N trường đầu khi so sánh với -f
- Ví dụ 8: Hiển thị tất cả các dòng trùng lặp với -D
Ví dụ 1: Lọc các dòng trùng lặp và hiển thị nội dung duy nhất
Trong trường hợp chỉ cần loại bỏ các dòng trùng lặp liền kề và giữ lại một bản ghi duy nhất cho mỗi nhóm, bạn có thể sử dụng uniq ở chế độ mặc định không kèm tùy chọn.
uniq vietnix.txt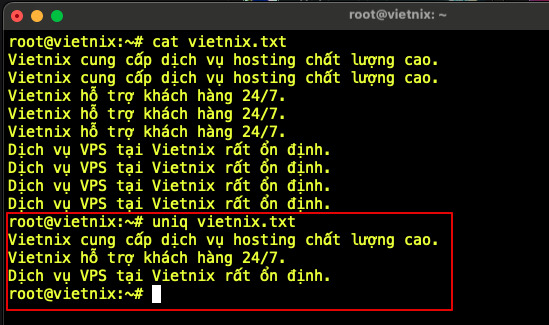
Lệnh này đọc nội dung input.txt, gộp các dòng giống hệt nhau đứng liên tiếp và chỉ hiển thị một dòng đại diện, giúp danh sách không còn các bản ghi trùng lặp liên tiếp.
Ví dụ 2: Hiển thị các dòng trùng và số lần trùng lặp
Khi cần vừa liệt kê nội dung trùng lặp vừa biết số lần mỗi dòng xuất hiện, bạn có thể dùng uniq với tùy chọn -c để thêm cột đếm ở đầu dòng.
uniq -c vietnix.txt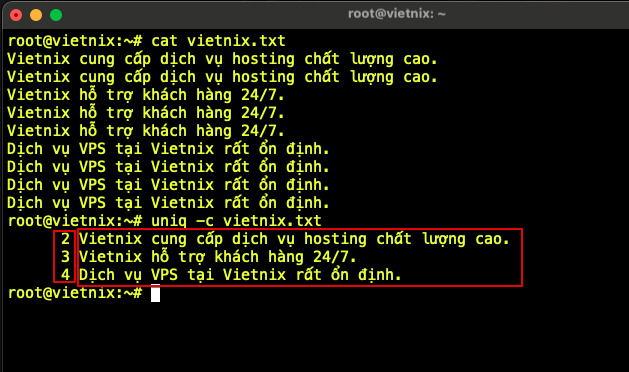
Giải thích: Cột đầu tiên thể hiện số lần lặp lại của dòng, cột thứ hai là nội dung dòng tương ứng, nhờ đó có thể nhanh chóng đánh giá tần suất xuất hiện của từng giá trị.
Ví dụ 3: Chỉ hiển thị các dòng bị trùng lặp và các dòng duy nhất
Nếu muốn tách riêng các dòng trùng lặp và các dòng chỉ xuất hiện một lần, uniq cung cấp hai tùy chọn -d và -u để xử lý từng nhu cầu.
uniq -d input.txt # Chỉ hiển thị các dòng bị trùng lặp
uniq -u input.txt # Chỉ hiển thị các dòng duy nhất (không trùng)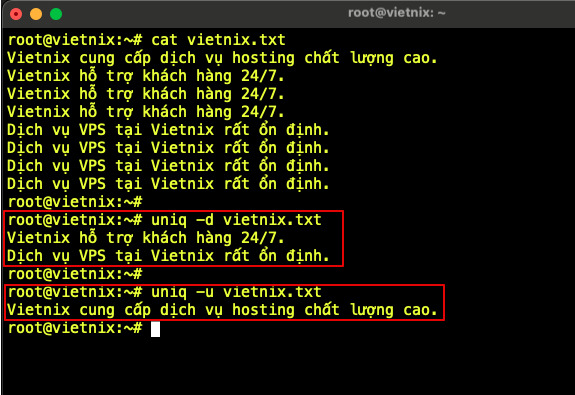
Giải thích: Option -d chỉ hiển thị ra những dòng xuất hiện từ hai lần trở lên và loại bỏ các dòng chỉ xuất hiện một lần, trong khi option -u thực hiện điều ngược lại, chỉ hiển thị các dòng duy nhất không có bản ghi trùng kề.
Ví dụ 4: Lọc trùng không phân biệt chữ hoa/chữ thường
Khi dữ liệu chứa cùng một nội dung nhưng khác nhau về chữ hoa/chữ thường và cần coi chúng như một nhóm, bạn có thể sử dụng tùy chọn -i để bỏ qua phân biệt này.
uniq -i input.txtGiải thích: Uniq so sánh nội dung dòng theo cách không phân biệt chữ hoa/chữ thường, nên các dòng như Nguyenhung, nguyenhung hay NGUYENHUNG được xử lý như một dòng trùng lặp duy nhất.
Ví dụ 5: Giới hạn so sánh theo N ký tự đầu dòng với -w
Trong một số trường hợp, chỉ phần đầu dòng mang ý nghĩa để xét trùng (ví dụ mã sản phẩm, tiền tố chung), có thể yêu cầu uniq chỉ so sánh một số ký tự đầu tiên.
uniq -w 10 nguyenhung_short.txtGiải thích: Lệnh chỉ so sánh 10 ký tự đầu của mỗi dòng, các dòng có 10 ký tự đầu giống nhau được coi là trùng, bất kể phần nội dung phía sau có khác nhau.
Ví dụ 6: Bỏ qua N ký tự đầu dòng khi so sánh với -s
Khi vài ký tự đầu dòng là thông tin không cần xét trùng (như timestamp, ID tự tăng), có thể yêu cầu uniq bỏ qua đoạn này trước khi so sánh.
uniq -s 3 input.txtGiải thích: Uniq bỏ qua 3 ký tự đầu của mỗi dòng, chỉ sử dụng phần còn lại để xác định các nhóm trùng lặp, phù hợp với file log có tiền tố cố định theo thời gian.
Ví dụ 7: Bỏ qua N trường đầu khi so sánh với -f
Với file dữ liệu dạng nhiều cột phân tách bằng khoảng trắng, đôi khi chỉ cần xét trùng bắt đầu từ cột thứ 2 trở đi và bỏ qua các cột đầu.
uniq -f 1 input.txtGiải thích: Tùy chọn -f 1 khiến uniq bỏ qua trường thứ nhất trong mỗi dòng khi so sánh, chỉ dựa vào các trường tiếp theo để phát hiện trùng lặp, thường dùng khi cột đầu là index hoặc mã không quan trọng.
Ví dụ 8: Hiển thị tất cả các dòng trùng lặp với -D
Trong trường hợp cần xem toàn bộ bản ghi nằm trong các nhóm trùng lặp chứ không chỉ một dòng đại diện, uniq cung cấp tùy chọn -D.
uniq -D vietnix.txtGiải thích: Lệnh này hiển thị tất cả các dòng thuộc nhóm trùng, giúp kiểm tra chi tiết từng bản ghi trùng lặp trong file, hỗ trợ tốt cho bước rà soát và phân tích dữ liệu.
Lưu ý khi thao tác với lệnh uniq Linux
Khi thao tác với lệnh uniq trên Linux, bạn cần nắm rõ một số điểm sau để tránh hiểu nhầm kết quả và kết hợp đúng với các lệnh khác:
- Uniq chỉ xử lý các dòng trùng lặp liền kề: Lệnh uniq chỉ phát hiện và loại bỏ các dòng giống nhau khi chúng đứng cạnh nhau trong file hoặc luồng dữ liệu, nên nếu dữ liệu chưa được sắp xếp, các dòng trùng nhưng nằm xa nhau sẽ không được xử lý đầy đủ.
- Nên kết hợp sort trước khi uniq để lọc trùng toàn file: Để đảm bảo mọi dòng trùng trong toàn bộ file được gom lại và uniq xử lý chính xác, nên dùng
sort file | uniqhoặcsort -u filetrong các trường hợp cần loại bỏ trùng trên phạm vi toàn bộ dữ liệu. - Chú ý khi dùng uniq -c với file chưa sắp xếp: Tùy chọn
-cchỉ đếm số lần xuất hiện liên tiếp, vì vậy nếu file không được sort trước, số đếm phản ánh số lần lặp liên tiếp chứ không phải tổng số lần xuất hiện trong toàn bộ file - Phân biệt uniq với sort -u: uniq chỉ lọc trên các dòng liền kề trong khi
sort -uvừa sắp xếp vừa loại bỏ trùng, do đó trong nhiều trường hợp cần kết quả đã sắp xếp và không trùng,sort -ucó thể thay thế chuỗisort | uniq. - Lưu ý khi dùng các tùy chọn -w, -s, -f: Các tùy chọn giới hạn hoặc bỏ qua ký tự/trường khi so sánh (
-w N,-s N,-f N) chỉ ảnh hưởng đến phần so sánh trùng lặp, không thay đổi nội dung dòng xuất ra, nên cần kiểm tra kỹ logic dữ liệu để tránh nhóm nhầm các dòng không thực sự trùng nhau. - Hoạt động tốt với stdin và pipeline: uniq thường được dùng phía sau các lệnh như
sort,cat,grepthông qua pipe để xử lý trực tiếp luồng dữ liệu, vì vậy nên ưu tiên pipeline thay vì tạo nhiều file trung gian khi thao tác với dữ liệu lớn.

Câu hỏi thường gặp
Uniq Linux có bắt buộc phải dùng với sort không?
Không bắt buộc, uniq linux vẫn hoạt động với file/luồng dữ liệu chưa sort, nhưng lệnh chỉ xử lý các dòng trùng lặp liền kề, nên để loại bỏ trùng trên toàn bộ file, thường cần kết hợp sort file | uniq hoặc dùng sort -u.
Khác biệt giữa uniq Linux và sort -u là gì?
uniq linux chỉ loại bỏ các dòng trùng lặp liền kề và không tự sắp xếp dữ liệu, trong khi sort -u vừa sắp xếp vừa loại bỏ tất cả dòng trùng trong một bước, phù hợp khi cần danh sách đã sort và không trùng.
Uniq Linux có thể đọc/ghi trực tiếp giữa hai file không?
Có, uniq Linux hỗ trợ truyền trực tiếp từ file đầu vào sang file đầu ra với cú pháp uniq input.txt output.txt, trong đó input.txt là file nguồn và output.txt là file chứa kết quả sau khi xử lý trùng lặp.
Có thể thấy uniq linux là một tiện ích xử lý văn bản đơn giản nhưng hữu ích, đặc biệt khi kết hợp với sort, grep, cat hoặc các pipeline khác để lọc trùng, đếm tần suất và trích xuất các dòng duy nhất trong file log, danh sách dữ liệu hay output của lệnh hệ thống. Khi nắm rõ cách uniq hoạt động trên các dòng trùng lặp liền kề, hiểu đúng ý nghĩa từng tùy chọn và áp dụng kèm các lưu ý về sắp xếp dữ liệu đầu vào, bạn có thể xây dựng các câu lệnh uniq linux ngắn gọn nhưng đáp ứng tốt nhu cầu phân tích và tối ưu dữ liệu trên môi trường Linux thực tế.




